
Pubblicato il 23 marzo 2020 su Martin Ingram’s Blog – Traduzione di Edoardo Salvati
// Visto che il tennis è sospeso, ho pensato che fosse interessante cercare di individuare alcune tendenze nell’evoluzione degli stili di gioco. È da tempo che avevo intenzione di applicare un modello diffuso nel campo dell’apprendimento automatico, il Latent Dirichlet Allocation (LDA), ai dati derivanti dal Match Charting Project. Per chi non lo conoscesse, il Match Charting Project è uno sforzo colossale di diversi volontari che codificano con minuzia la sequenza dei colpi di ciascuno scambio di un’intera partita di tennis. Rappresenta di gran lunga la più completa risorsa informativa sulle partite. Gli altri database pubblicamente disponibili infatti si limitano, nei casi migliori, a descrivere la sequenza dei colpi senza fornire altri dettagli sullo scambio.
Il modello LDA nell’apprendimento automatico
Che cos’è il Latent Dirichlet Allocation? Si tratta di un modello inizialmente concepito per trovare specifici temi o categorie in un insieme di documenti scritti in linguaggio naturale. Costituisce la base di analisi del LDA una serie di documenti, come potrebbero essere degli articoli del New York Times. Ciascun documento è identificato dalla frequenza con cui ogni parola, o termine, è citata. Ad esempio, se un documento consiste solo nella frase “ciao ciao arrivederci”, viene identificato con (ciao, 2), (arrivederci, 1), perché ciao compare due volte e arrivederci una.
L’idea centrale del LDA è il tema. Un tema definisce quanto ogni termine è probabile. Negli articoli del New York Times, si può pensare che ricorra un tema “politica” che assegna un’alta probabilità a parole come “politico”, “congresso”, “elezione”, e così via.
Si può naturalmente pensare che ogni documento è generato da un singolo tema. È una modalità legittima, e darebbe luogo a un modello combinato. Tuttavia, molti documenti contengono molti temi. Ad esempio, è ipotizzabile che il tema “politica” appaia spesso in articoli che hanno a che fare anche con l’economia. Il LDA ne tiene conto modellando ogni articolo come un misto di temi: un documento potrebbe essere 60% economia e 40% politica. Questo significa che ogni parola arriva al 60% probabilmente dal tema economia e al 40% dal tema politica.
Come si comporta il LDA nella pratica?
In presenza di un insieme di documenti con il rispettivo conteggio delle parole e con il numero di temi da cercare, il LDA è in grado di trovare quei temi – come sono distribuiti rispetto alle parole – e quanto è probabile che ogni documento vada ricollegato a un tema, quindi come sono distribuiti rispetto ai temi.
Il LDA per il Match Charting Project
In che modo il LDA può essere applicato al Match Charting Project? L’interrogativo primario riguarda a quali elementi del tennis corrispondono le “parole” e i “documenti”. La risposta non è così scontata, e ho considerato diverse possibilità. Quella da cui alla fine sono partito, principalmente perché era la più facile grazie al preciso lavoro di riordino dei dati da parte di Jeff Sackmann, è la seguente:
- una parola equivale a un tipo di colpo. Il Match Charting Project prevede 17 tipi di colpi base, come dritto e rovescio a rimbalzo piatto o in topspin, dritto e rovescio tagliato, volée di dritto e così via, per citarne alcuni (di più su questo a breve)
- ogni documento equivale a una combinazione giocatore-partita. Ad esempio, una partita tra Roger Federer e Rafael Nadal determina due documenti, uno per Federer, identificato da quanto spesso colpisce ogni colpo, e un altro per Nadal.
Pur nella convinzione che sia un punto di partenza ragionevole, ci sono ovvi margini di miglioramento. Un’aggiunta relativamente semplice è quella di procedere a un’ulteriore categorizzazione di tutti i colpi in funzione della direzione in cui sono stati colpiti. Un’altra idea può essere quella di raggruppare i colpi in sequenze di due colpi consecutivi: ad esempio (dritto a rimbalzo incrociato piatto o in topspin, dritto a rimbalzo incrociato piatto in topspin) indica che il giocatore ha ricevuto un dritto a rimbalzo incrociato piatto o in topspin e ha risposto con lo stesso tipo di dritto. Si potrebbero integrare così informazioni sullo sviluppo di uno scambio. In ogni caso, era il sistema più facile da applicare e, come spero sarete d’accordo, produce già dei risultati piuttosto interessanti.
La finale di Wimbledon 2008
Per illustrare l’idea, quale migliore esempio se non la rappresentazione dell’incredibile finale di Wimbledon 2008 tra Federer e Nadal?
IMMAGINE 1 – Rappresentazione secondo il metodo LDA della finale di Wimbledon 2008
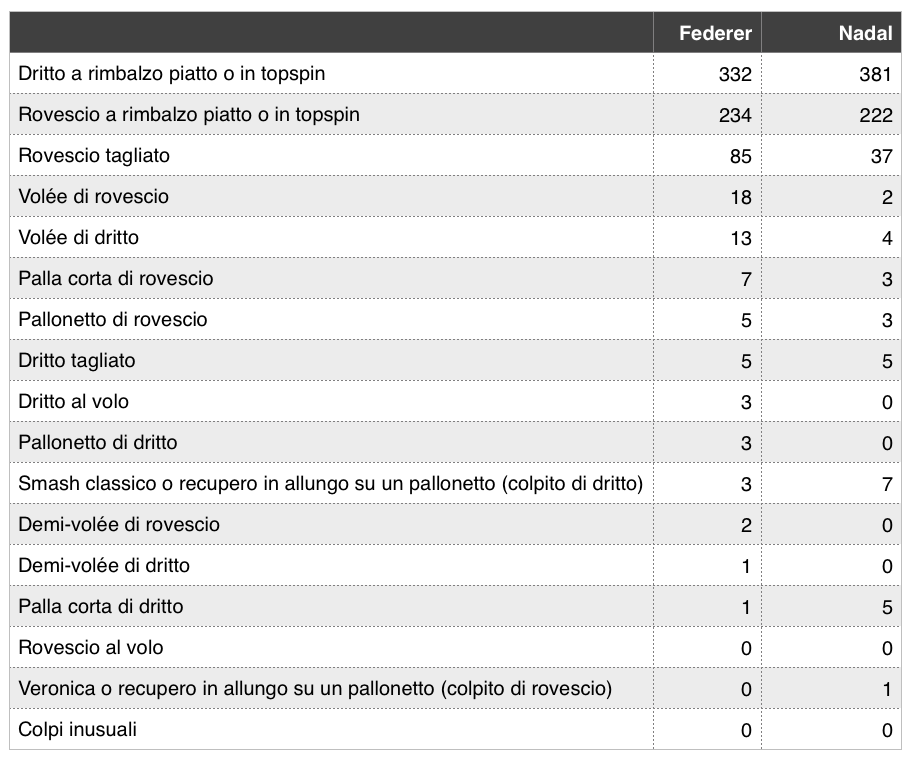
Ogni colonna rappresenta qui un “documento” e ogni fila una “parola”. Come ci si poteva aspettare, la maggior parte dei colpi sono stati colpi a rimbalzo, e la maggior parte di questi dal lato del dritto. Federer ha colpito più rovesci tagliati ed è venuto a rete più spesso, mentre Nadal ha colpito più dritti. Tornerò su questo esempio più avanti nel riepilogo dei risultati ottenuti con il LDA.
Complessivamente, al momento della stesura, ci sono 4938 documenti partite-giocatore, relativi quindi al circuito maschile. Non stupisce che i giocatori più famosi sono anche quelli con più occorrenze, il solo Federer ne ha ben 417, ma si tratta comunque di una risorsa fondamentale. E il mio vivo ringraziamento va a tutti i volontari che hanno contribuito!
Aggiustamento del LDA
Nell’utilizzo del LDA, una scelta obbligata è quella del numero di temi da cercare. Non mi sono soffermato a lungo su questo aspetto. Come prima scelta, ho cercato di prendere il numero di elementi con la minore “perplessità”, un numero che ho facilmente calcolato con l’implementazione scikit-learn di Python che stavo usando. È emerso che quattro temi valutati sull’insieme di dati completo restituiscono il risultato migliore. Mi aspettavo un numero più alto, e non mi sento del tutto sicuro del mio metodo di selezione dei temi. Il timore è che quattro temi rischiano di essere una semplificazione eccessiva, anche se un numero ridotto ha il vantaggio di una maggiore immediatezza interpretativa contro, ad esempio, a dieci temi. Per ora quindi mantengo i quattro temi.
Temi
Questi sono i quattro temi che ho trovato, insieme alla loro distribuzione di probabilità rispetto ai colpi. Per facilitare la lettura, ho assegnato un nome a ciascuno. Per evitare eccessiva confusione, ho elencato solo i colpi con la probabilità più alta.
Tema 1, “Colpi da fondo”
54% rovesci a rimbalzo piatti o in topspin, 38% dritti a rimbalzo piatti o in topspin
Tema 2, “Colpi a rete”
28% volée di rovescio, 24% volée di dritto, 18% rovesci a rimbalzo piatti o in topspin, 10% dritti a rimbalzo piatti o in topspin, 6% smash normali, 4% demi-volée di rovescio, 3% rovesci tagliati, 3% demi-volée di dritto, 3% pallonetti di rovescio
Tema 3, “Scambio di dritto”
84% dritti a rimbalzo piatti o in topspin, 7% rovesci a rimbalzo piatti o in topspin, 4% rovesci tagliati
Tema 4, “Rovescio tagliato”
68% rovesci tagliati, 17% dritti a rimbalzo piatti o in topspin, 6% dritti tagliati, 3% rovesci a rimbalzo piatti o in topspin.
Cosa ne è di Federer e Nadal a Wimbledon 2008?
IMMAGINE 2 – Distribuzione di probabilità rispetto ai colpi per i quattro temi individuati per la finale di Wimbledon 2008

Osserviamo che il 54% dei colpi di Federer e Nadal rientrano nel tema Colpi da fondo, senza che vi sia in questo caso differenza tra i due. Federer è ricorso al tema Colpi a rete il 6% delle volte, mentre Nadal non lo ha mai praticamente fatto, con la probabilità di quel tema arrotondata a zero. Federer ha anche fatto più uso del tema Rovescio tagliato di Nadal. È interessante come Nadal è stato capace di fare intenso ricorso al tema dello Scambio di dritto. Infine, Federer ha usato il tema Rovescio tagliato più spesso di Nadal.
Giocatori rappresentativi di ciascun tema
Per una maggiore comprensione, l’immagine 3 mostra i giocatori con la più alta probabilità media di utilizzo di ciascun tema. Sono considerati solo i giocatori con almeno 20 partite nel database del Match Charting Project.
IMMAGINE 3 – Giocatori con la più alta probabilità media per tema
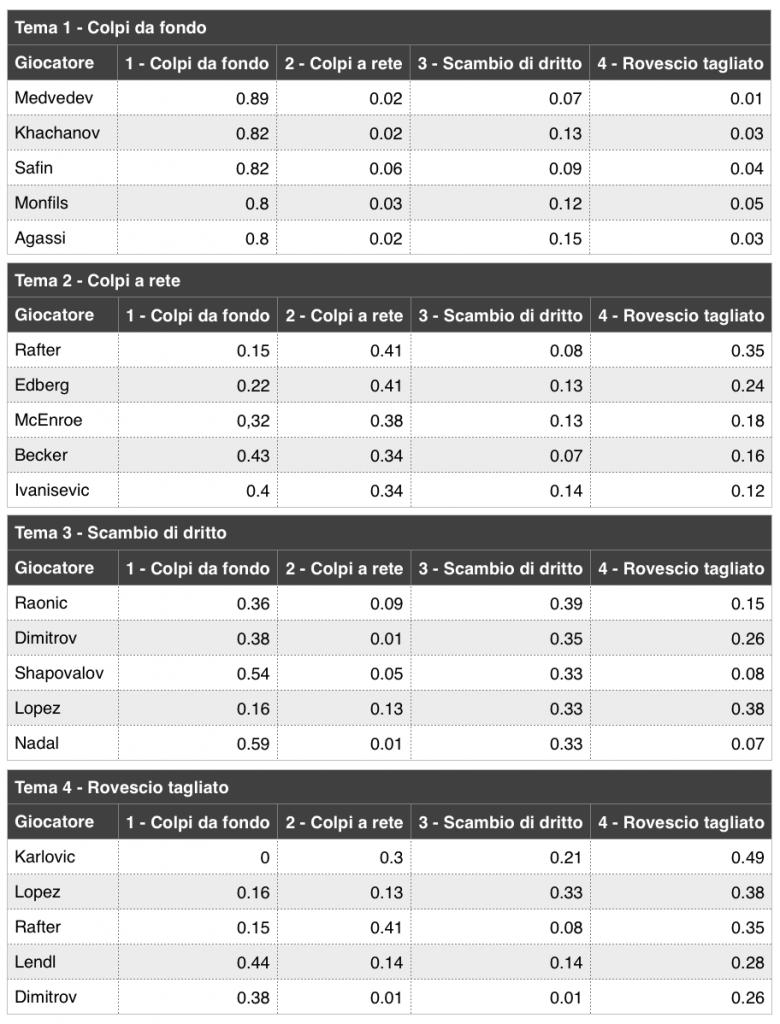
Quattro dei primi cinque giocatori nel tema Colpi da fondo hanno avuto i loro periodo più redditizio negli anni 2000 e negli anni 2010, come era pensabile considerato il dominio del gioco da fondo nel tennis contemporaneo. Per questi giocatori la maggior parte della distribuzione dei colpi è nel tema Colpi da fondo, con qualche colpo nel tema Scambio di dritto.
Una vera testimonianza che il gioco al volo è un retaggio del passato arriva dai giocatori in cima all’elenco del tema Colpi a rete. Tutti e cinque hanno vinto Wimbledon almeno una volta. Patrick Rafter si mette in evidenza per un uso cospicuo del rovescio tagliato, mentre sembra che Boris Becker e Goran Ivanisevic fossero più disposti a scambiare anche da fondo rispetto agli altri tre.
I primi cinque nel tema Scambio di dritto sono tutti in attività. Milos Raonic appare come il più prone a colpire di dritto. Feliciano Lopez si fa notare per tagliare i colpi più degli altri, con Grigor Dimitrov al secondo posto in questo senso. Nadal usa quasi esclusivamente i temi Colpi da fondo e Scambio di dritto.
Ivo Karlovic è in cima al tema Rovescio tagliato. Hai mai colpito un rovescio a rimbalzo piatto o in topspin? Da quanto si vede in partita, non ne fa certamente un’abitudine. I prime cinque nel tema hanno tutti il rovescio a una mano, come ci si poteva aspettare.
Evoluzione dei temi nel tempo
Come sono cambiati gli stili nel corso degli anni? Per avere un’idea, ho deciso di inserire nello stesso grafico le probabilità medie dei temi di ogni anno dal 1980, regolarizzando poi il risultato
IMMAGINE 4 – Evoluzione dei temi nel tempo
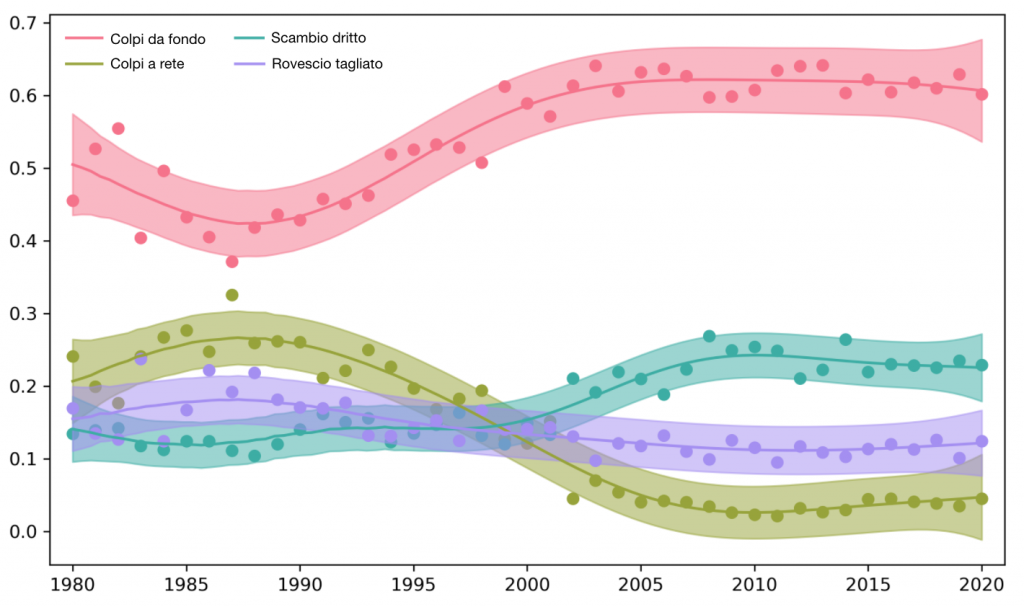
Il cambiamento più drastico a mio modo di vedere è il drammatico declino del gioco a rete. Per certi versi, sto dicendo un’ovvietà, tutti sanno che il servizio è volée è una tattica ormai superata. Ero però curioso di capire quando e quanto tempo fa è iniziato il declino. Nella versione regolarizzata, il tema Colpi a rete ha raggiunto l’apice nel 1986 per poi avviarsi alla ritirata intorno al 1990, fino a raggiungere il valore attuale del 5% verso il 2008. Contestualmente, come prevedibile, il tema Colpi da fondo è diventato più frequente, dal punto più basso del 45% nella metà degli anni ’80 fino al valore attuale del 60%.
Inoltre, è anche interessante che il tema Scambio di dritto, per quanto sempre presente, sia aumentato da un valore del 14% dei colpi intorno al 2000 fino a un valore attuale del 23%. Potrebbe essere indicazione che la tattica di colpire più dritti possibili si è diffusa da quel momento in avanti.
Mi piacerebbe sapere anche quanta parte di questi cambiamenti è legata ai diversi fattori di cui piace tanto dibattere agli appassionati. Gustavo Kuerten ha vinto il Roland Garros 1997 usando le famose corde in poliestere, anche se pare non fosse l’unico ad averle. Erano corde che consentivano di imprimere una maggiore rotazione alla palla e facilitare i passanti. Di sicuro il tema Colpi a rete era in fase calante in quel periodo, arrivato al 15% da un periodo d’oro del 25%, quindi era già successo qualcosa. In molti sostengono anche che le differenze tra superfici si sono livellate nel tempo. Non mi sembra così ovvio dal grafico visto che credo (forse erroneamente) che sia iniziato già nei primi anni 2000, ma può aver contribuito al continuo declino del gioco a rete in quel decennio.
Entropia
Sebbene il Match Charting Project sia la fonte più granulare che abbiamo, le partite in esso contenute non sono necessariamente un insieme rappresentativo. Non ho verificato le situazioni di squilibrio, ma è possibile che vi siano più dati per partite sull’erba negli anni ’80 che in quelli a seguire, che potrebbe spiegare parte del calo iniziale. È altresì possibile che i giocatori che compaiono nel database siano una specifica selezione, e che i giocatori che hanno continuato a portare avanti la causa del servizio è volée negli anni ’90 riscuotano meno fascino tra i volontari che raccolgono i dati. Fondamentale quindi leggere questi risultati con il beneficio del dubbio.
Per arrivare in ultimo alla domanda del titolo dell’articolo, ovvero se il tennis è diventato più prevedibile, ho analizzato l’entropia media delle partite per anno. A grandi linee, l’entropia in questo caso è solo una misura dell’ampiezza distributiva delle probabilità. Ad esempio, se tutte le partite hanno usato un unico tema, l’entropia sarebbe vicina allo zero, mentre con un uso uguale di tutti i temi, l’entropia sarebbe di circa 1.39.
IMMAGINE 5 – Entropia come misura dell’imprevedibilità del tennis
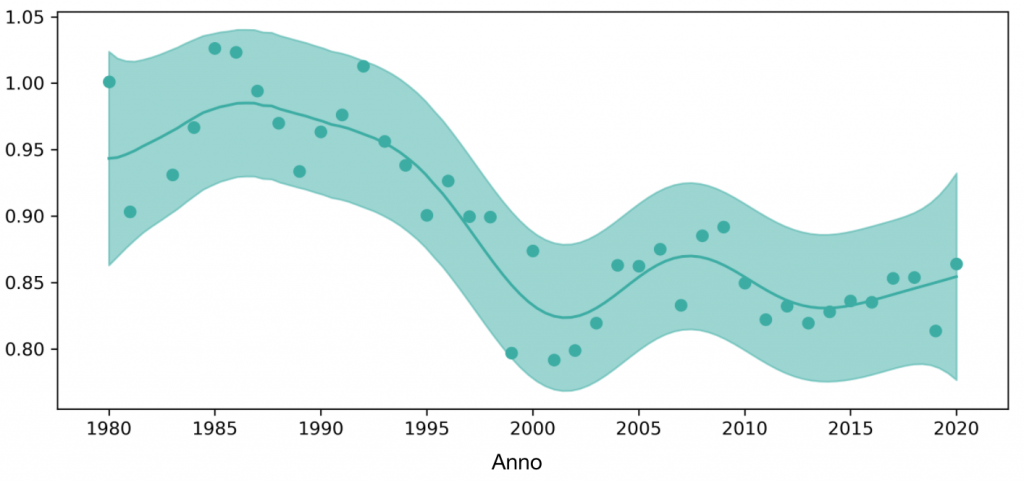
Il grafico suggerisce che l’entropia è diminuita e che i giocatori sono diventati più prevedibili nell’uso dei temi. Un possibile inizio del declino è nei primi anni ’90, con un’accelerazione sostenuta verso la fine del decennio. Questo però non deve far pensare che il tennis sia meno interessante: anche nel tema dei Colpi da fondo ricorrono molte sfumature che questo semplice modello non incorpora.
Conclusioni
Spero di avere la vostra approvazione sul fatto che un primo esame dei dati del Match Charting Project con il metodo Latent Dirichlet Allocation ha prodotto risultati interessanti. Ci sono molte estensioni del LDA che potrebbero essere applicate, come il LDA dinamico, che elabora un modello dell’evoluzione dei temi nel tempo e cerca anche di indagare quali documenti hanno cambiato temi. Come ho detto, vorrei procedere a usare più temi nel LDA o forse definirne un numero automatico con modelli gerarchici di temi, oltre a includere più dettagli sugli scambi. C’è ancora molto da fare! ◼︎
Has tennis become more predictable? An initial look with a topic model
